SRE 日常的事務是保持系統的穩定,因此會有許多日常維運,以及處理重要事件時相關的工作。前面提到的工作大多沒有結束的日期,是屬於會重複發生或要持續改進的工作,但也會有另一種工作,屬於與 SRE 有關,但可能只是單次的任務而已。這個「重要事件系列」就是為了介紹類似這樣的工作。
嚴格來說, ISO 27001 的工作,因為要持續維護證照的關係,因此工作本身也不算是一次完成後就結束者。但因為因應 ISO 27001 而出現的改善事項,大部分都屬於一次性的改善,因此筆者這邊仍然將其列入重要事件簿系列中。而所謂單次事件與持續維護的事件之間,界線也不會這麼清楚就是了,比如最初期提到的棒球賽系列文章,也可以算是重要事件。
ISO 27001 比較偏向資安,其實與 SRE 不一定有直接關聯,因此也是跟據產品經理與團隊的討論之後,決定會分派給 SRE 的工作。不過,與之前「日常維運5:IAM user定期盤點」中提到的一樣,某些可能傳統上認知不屬於 SRE 的工作,剛好在敝公司是歸 SRE 管,而 ISO 27001 在這一塊有關資安相關的處理,因為暫時沒有專門的資安部門的關係,工作就先暫時落到 SRE 身上了。
會提到這部分主要還是因為,希望在向讀者介紹 SRE 相關工作的時候,能夠盡可能籬清一些可能容易讓人誤會的部分。
ISO/IEC 27001,按照維基百科的說明,全名為「《資訊科技—安全技術—資訊安全管理系統—要求》(Information technology — Security techniques — Information security management systems — Requirements)」,是一種用來規範資訊安全管理的國際標準。
在〈特別監控系統2: 資料庫異常登入監控〉這篇文章中,筆者曾經用便當的食品安全來做比喻。便當本身的口味如果是一種 feature 的話,那不同口味的便當就相當於是擁有不同 feature 的產品。但 ISO 27001 更關心的不是便當的口味,反而是便當食材的食品衛生安全問題。關心這件事情雖然不會直接影響吃飯的人,但在比如食物中毒之類的食安危機時,就會起到關鍵性的作用。
在軟體開發上, ISO 27001 不會關心產品的 feature ,而是關心與資安相關的事務。比如資料庫是否有定期進行備份之類的行動。因此,這是一個不會直接影響使用者體驗的事務,但可以增加這個系統的安全性與應對風險時的軔性。換個說法來講,這是一個平常感覺沒有特別用處,但在系統遇到重大危機的時候可以有所幫助的工作。
透過一系列針對系統的改善,再經過專業團隊的認證之後,該專案就可以獲得一個 ISO 27001 的證書。後續則會有一年一度的稽核,需要每次檢核都有受到認證,才可以繼續維持這個證書。
在稽核過後,通常會跟據風險等級列出不同的不符合項目,但不符合不一定代表拿不到證書,而是需要制定相關的改善計畫,並在下次的稽核日期中確認改善的進度。雖然之前已經有介紹過〈特別監控系統2: 資料庫異常登入監控〉,但在這邊從整個改善過程的角度,來向讀者分享一個筆者當時負責過的改善計畫,從準備到完成有發生過什麼事情。
在稽核完後得到的其中一個改善項目,是希望能夠針對資料庫這個服務行一般的日誌蒐集。這個要求並非期待專案會需要在日誌蒐集後進行下一步的處理,而是要蒐集後把 log 給整理到其中一個地方而已。
因為我們透過 AWS RDS 來架設資料庫的服務,而這個要求在 RDS 中剛好有一個相對應的功能,被稱之為 RDS Audit Log (文件)。因此一開始,筆者原本以為只要啟用該功能後,就可以理所當然地解決這個問題。
沒有意外的話,果然要出意外了。在隔了一個週末後,我們收到了預算爆表,要緊急關這個設定的請求。當時預算的圖表如下:
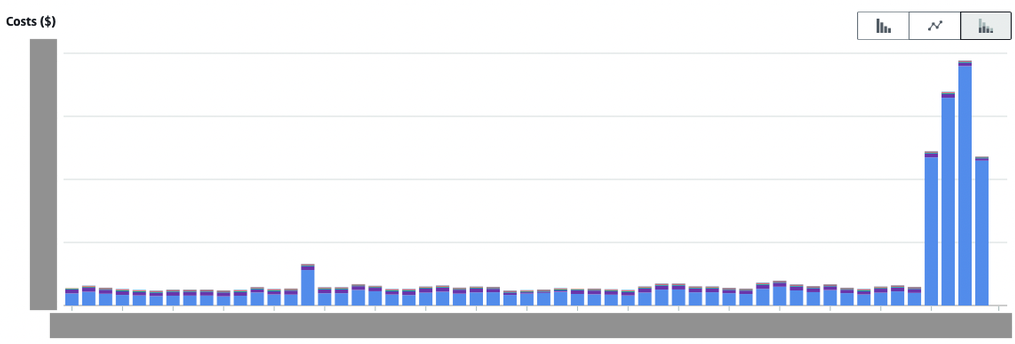
各位可以看到後面的預算大約是原本的至少十倍以上,而且這並非是針對該單一功能,而是整個帳號的預算的十倍。
雖說是緊急關閉,但因為是在正式環境所做的改動,因此還是需要透過產品經理的同意,並做出不影響服務的保證之後才能關閉,因此實際上也還是要花上一點時間溝通或同步資訊。
而之前有曾經聽資深前輩分享過,做資訊安全本身就是要砸錢去做的,這件事情也是現在才開始有比較實際的感覺。
無論如何,在緊急關閉之後,下一步就是尋找原因並推出下次的解決方法了。
首先,預算會超乎預期,當然最主要就是在於我們的 RDS Log 數量太過龐大的關係。 RDS Audit Log 在啟用之後,會將資料庫的日誌傳送到 CloudWatch Log 做保存。當初在計算預算的時候,雖然思考過了在 CloudWatch 保存(retention)的費用,但這次造成預算爆表的主要原因,卻是 RDS 在把 Audit Log 給傳送到 CloudWatch 這個過程中的傳輸費。
釐清了主要預算爆表的原因後,我們初步得到了以下三種可能的解決方案:
server_audit_events、server_audit_excl_users、server_audit_incl_users),來選擇性地傳送必要的資訊。在前面的三種方案,除去第三種單純參考用的教學外,我們一開始是傾向於使用第一種的。最重要的理由還是在於說,我們想要儘可能地減少後續維護上的成本。跟據第二種方式的教學,雖然它宣稱可以減少 90% 以上的預算,但我們還沒有親自證實過這件事情。而它所使用的方式除了會增加後續 Lambda 的維護成本外,我們也不是很肯定該架構有沒有可能會出現我們預期之外的狀況,比如串接上的問題或是後續維護上的問題。
相較於此,第一種解決方式的資訊來源是官方的資料,而且所有的改動都是在 RDS 原本的設定中去調整參數,因此相對而言不只不需要維護自己寫的程式,在架構上也非常單純好維護。
因此從一開始,我們就決定要往第一種方向去進行深入的研究。
server_audit_events主要是在選擇不同的資料庫事件,參數選擇上總共有五種,分別是CONNECT、QUERY、QUERY_DCL、QUERY_DDL、QUERY_DML、TABLE;server_audit_excl_users 與 server_audit_incl_users則是用來選擇使用者的身份,比如我們可以選擇只記錄某些使用者的操作行動而已。可以參考以下的截圖:

參考了 ISO 27001 的要求之後,一開始筆者原本認為只要開啟CONNECT和QUERY_DDL兩種即可,因此筆者隨即開始在測試環境中的資料庫開始進行相關測試。雖然的確有降低成本的狀況,但非正式與正式環境之間的流量差異具大,因此要估算出正式環境的狀況仍然相當困難。最重要的是,其實當時粗估的結果似乎仍比預期還要高上一些,因此曾一度想放棄這個方式,改嘗試前面提過的第二種方案。
幸運的是,因為資料庫要開始切分不同使用者的關係(也是因為 ISO 27001 的要求,與「特別監控系統2: 資料庫異常登入監控」這篇文章有關),因此我們反而可以從使用者身份這個角度切入了。在切分使用者之前,我們的一般開發者和程式共用了同一組資料庫帳號,之後我們則是每一個開發者都擁有自己的一組資料庫帳號。
因為有這個區分,我們可以透過只選擇開發人員的方式,來大幅減少日誌數量。因為開發人員實際上在正式環境中存取資料庫的機會非常少,因此需要的花費可以說是幾乎沒有。原本預期使用者的增減會是後續維護上的成本(比如新增一個使用者,就會需要新增一個日誌規則),但也因為可以透過server_audit_excl_users來直接過濾「非系統使用者」而沒有這個成本。唯一可惜的是CONNECT不能區分使用者,但已經非常夠用了。
在成功減少成本後,這題也宣告解決。下一篇將會分享 ISO 27001 其它的定期工作,並分享一下預期之外的挑戰和良好心態的建立。

